

In the world of search engine optimization (SEO), the WordPress robots.txt file is a powerful tool. This seemingly simple file is a cornerstone of how search engines interact with your website, guiding them on which parts to crawl and which to ignore.
- What is the Robots.txt File?
- What Are Some Key Considerations To Keep In Mind When Optimizing Your Robots.txt File For Mobile Crawlers?
- Where Is the WordPress Robots.txt File Located?
- The Virtual Robots.txt File in WordPress
- Creating and Editing a Physical Robots.txt File in WordPress
- Best Practices for Using Robots.txt in WordPress
- How Can You Test And Troubleshoot Your WordPress Robots.txt File?
- What Was The Purpose Of The Google Crawl Delay Limit Directive in Robots.txt Files?
- What Are Some Key Aspects To Consider When Troubleshooting A Robots.txt File for WordPress Websites?
- How Can You Prevent Aaccess To A Specific Folder Or File On Your WordPress Site?
- Final Thoughts

But where is this mysterious robots.txt file located in your WordPress site?
Stick with us, and you’ll not only discover its location but also learn more about the importance and effective management of this pivotal file.
What is the Robots.txt File?
Before we dive into its location, let’s briefly cover what the robots.txt file is.
The robots.txt file is a protocol, or a set of rules, that instructs search engine bots on how to crawl and index pagesIn WordPress, a page is a content type that is used to create non-dynamic pages on a website. Pages are typica... More on your website. It’s part of the Robots Exclusion Protocol (REP), a group of web standards that regulate how bots crawl the web, access and index content, and serve that content up to users.
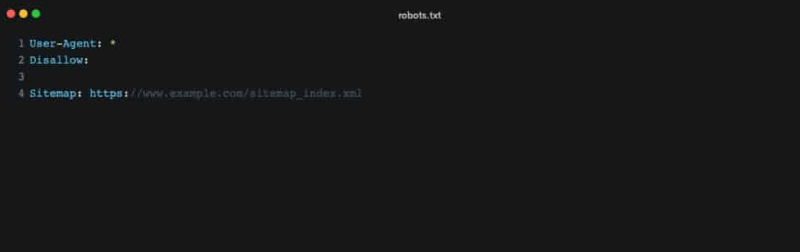
The robots.txt file can include directives to allow or disallow crawling of specific directories, individual files, or even entire sections of your site. It can also point bots to your XML sitemap for a streamlined crawling process.
What Are Some Key Considerations To Keep In Mind When Optimizing Your Robots.txt File For Mobile Crawlers?
Optimizing your robots.txt file for mobile crawlers is crucial in today’s mobile-centric internet landscape. Here are key considerations to keep in mind:
- Mobile-Friendly Directives: Ensure your robots.txt file includes directives that cater specifically to mobile user agents like Googlebot-Mobile. This ensures mobile-friendly or responsive pages are accessible to mobile crawlers.
- Prioritize Essential Resources: Important resources such as CSS and JavaScript files are vital for rendering mobile pages accurately. Avoid blocking these resources in your robots.txt to allow mobile crawlers to effectively analyze and display your site on mobile devices.
- Test and Validate: Regularly test your robots.txt file using tools like Google’s robots.txt Tester. This helps identify and resolve any issues that could prevent mobile crawlers from accessing critical content on your site.
- User-Agent Specific Rules: Consider implementing specific rules for mobile crawlers versus desktop crawlers. Tailoring your robots.txt file for different user agents can optimize indexing for both mobile and desktop versions of your site.
- Continuous Updates: Mobile SEO standards and crawling technologies evolve rapidly. Regularly update and audit your robots.txt file to align with current best practices and ensure optimal performance on mobile search engines.
By addressing these considerations, you can effectively optimize your robots.txt file for mobile crawlers. This not only enhances visibility but also improves user engagement on mobile devices, contributing to a better overall user experience and SEO performance.
Where Is the WordPress Robots.txt File Located?
Now that we know what the robots.txt file does, let’s answer the central question: where is it located?
In a WordPress site, the robots.txt file is typically located in the root directory. This means that if your site’s URL is https://www.yoursite.com, you can access your robots.txt file by appending “/robots.txt” to the end of your site’s URL, like so: https://www.yoursite.com/robots.txt.
However, there’s a catch. WordPress doesn’t automatically create a physical robots.txt file. Instead, if one doesn’t exist, WordPress creates a virtual robots.txt file.
The Virtual Robots.txt File in WordPress
A virtual robots.txt file is dynamically generated by WordPress itself whenever a bot requests it. If you haven’t manually created a robots.txt file in your site’s root directory, WordPress will serve this virtual one. It’s a clever system that ensures there is always a basic robots.txt file in place, even if you haven’t created one yourself.
By default, the virtual robots.txt file created by WordPress includes directives that prevent search engines from crawling your admin area and other sensitive parts of your site, while allowing them to access the rest.
Creating and Editing a Physical Robots.txt File in WordPress
Although the default virtual robots.txt file is adequate for many WordPress websites, there may be times when you want to customize the instructions to web crawlers. For this, you’ll need to create a physical robots.txt file.
You can create a robots.txt file by simply creating a new text file and naming it robots.txt. Then, you fill it with the rules you want the web crawlers to follow when they visit your site.
Once you’ve created your custom robots.txt file, you upload it to the root directory of your WordPress site using an FTP client or the file manager in your hosting control panel. From this moment on, the physical file will override the virtual one, and WordPress will stop generating the virtual robots.txt.
Best Practices for Using Robots.txt in WordPress
While having the power to dictate how search engines crawl your website might feel exciting, it’s crucial to use this power responsibly. Misusing the robots.txt file can lead to significant parts of your site being excluded from search engines, which can severely impact your SEO.
Here are a few best practices to keep in mind:
How Can You Test And Troubleshoot Your WordPress Robots.txt File?
Testing and troubleshooting your WordPress robots.txt file is essential to ensure that search engine crawlers can effectively navigate and index your website. Here’s a detailed guide on how to test and resolve issues with your robots.txt file:
Step-by-Step Guide to Testing Your WordPress Robots.txt File
Step 1: Confirm File Accessibility First, verify that your robots.txt file is accessible by typing your website’s URL followed by /robots.txt (e.g., https://www.yourwebsite.com/robots.txt) in your web browser’s address bar. This should display the content of your robots.txt file. If it doesn’t, check the file’s location or permissions.
Step 2: Use the Curl Command For a more technical approach, use the Curl command to fetch your robots.txt file. Open your command line interface and type:

This command confirms whether the file is retrievable, simulating the actions of search engine crawlers.
Step 3: Employ Google’s Robots.txt Tester Utilize Google’s Robots.txt Tester tool for further troubleshooting:
- Log into your Google Search Console.
- Navigate to the ‘Settings’ menuIn WordPress, a menu is a collection of links that are displayed as a navigation menu on a website. Menus are ... More and find the ‘robots.txt tester’ tool.
- Use this tool to fetch your robots.txt file. It not only retrieves the file’s content but also identifies any errors or warnings present.
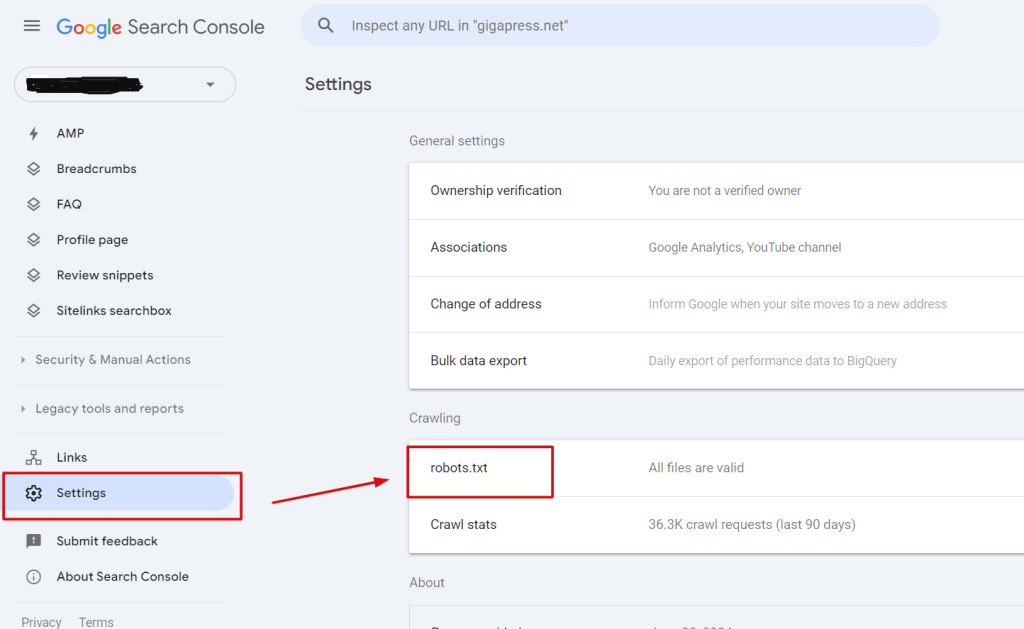
Step 4: Review and Address Issues After fetching your robots.txt file with Google’s tool, carefully review any errors or warnings flagged. This tool provides insights into sections of your file that may unintentionally block search engine bots or expose areas you intended to keep private.
Step 5: Make Adjustments and Re-test Based on Google’s feedback, make necessary adjustments to your robots.txt file. Update the file with corrections and repeat the testing process to ensure all identified issues are resolved. Regular monitoring and testing after updates help maintain optimal indexing of your site.
By following these steps, you can ensure that your WordPress robots.txt file effectively guides search engine crawlers, thereby enhancing your site’s SEO performance and visibility online.
What Was The Purpose Of The Google Crawl Delay Limit Directive in Robots.txt Files?
The Google Crawl Delay Limit directive in robots.txt files was created to regulate how frequently Google’s bots access web pages on a server. Its primary purpose was to allow webmasters to specify a waiting period for Googlebot between page requests. This feature was beneficial for maintaining stable server performance by preventing excessive load, ensuring servers could operate efficiently without becoming overwhelmed by a rapid influx of requests. By controlling the crawl rate, webmasters could manage server resources effectively and maintain a smooth browsing experience for users accessing their websites.
What Are Some Key Aspects To Consider When Troubleshooting A Robots.txt File for WordPress Websites?
When troubleshooting a robots.txt file for WordPress websites, several key aspects should be considered to ensure effective performance:
- Check for Errors: Errors in your robots.txt file can prevent search engines from properly indexing your site. Utilize tools like Google’s Robots Testing Tool to verify the file for any syntax mistakes or incorrect rules. This ensures that all directives are accurately formatted and do not hinder search engine access to important content.
- Avoid Over-Restriction: Ensure that your robots.txt file isn’t overly restrictive, as this could unintentionally block search engines from accessing critical pages. Use Google Search Console to review which areas of your site are being blocked and adjust directives accordingly to maintain visibility.
- Grant Access to Essential Resources: Make sure that essential resources such as CSS, JavaScript, and images are accessible to search engine bots. These elements are crucial for proper site rendering and user experience, so they should not be blocked in the robots.txt file.
- Precision in Directives: Directives in the robots.txt file should be precise and targeted to specific bots. This prevents any misunderstandings or miscommunication that could arise if directives are too broad or vague.
- Optimize for Mobile Crawlers: With the rise of mobile browsing, optimize your robots.txt settings to ensure mobile crawlers can access and index mobile-friendly content on your site. This includes verifying that directives cater to mobile user agents like Googlebot-Mobile.
By maintaining vigilance over your robots.txt file and implementing these considerations, you can effectively troubleshoot and optimize it for improved visibility and accessibility in search engine results. This proactive approach helps ensure your WordPress site is properly indexed and accessible to both desktop and mobile users.
How Can You Prevent Aaccess To A Specific Folder Or File On Your WordPress Site?
Managing access to specific folders or files on your WordPress site is crucial for security and SEO optimization. Here’s how you can effectively control access using the robots.txt file:
- Improving SEO and Bandwidth Management with robots.txt
The robots.txt file plays a vital role in SEO by guiding search engine crawlers on which parts of your site to index. By using Disallow directives, you can prevent crawlers from accessing non-essential or sensitive areas. This directs their focus to more valuable content, enhancing SEO efficiency. Moreover, restricting access conserves bandwidth by reducing unnecessary crawler traffic to these sections. - Examples of Files and Directories to Block
Certain files and directories should be blocked for security and privacy reasons. For instance:- /wp-admin/: This directory houses the WordPress admin area, where sensitive site management functions are performed. Blocking it prevents unauthorized access attempts.
- /wp-login.php: This file is used for user logins. Blocking it protects against brute-force attacks and unauthorized login attempts.

- Blocking Specific Areas Using robots.txt
To block access to specific areas of your WordPress site, follow these steps:- Open your robots.txt file located in the root directory of your site.
- Use Disallow directives followed by the paths of the directories or files you want to restrict. For example:

Save the changes to your robots.txt file. This tells search engine crawlers not to index or follow links to the specified areas.
By implementing these measures, you can enhance the security of your WordPress site and optimize its SEO performance. Restricting access to sensitive areas ensures that only authorized users interact with critical functionalities, safeguarding your site from potential threats and improving its overall search engine visibility.
Final Thoughts
In conclusion, the WordPress robots.txt file, whether physical or virtual, is located in the root directory of your website. Understanding and managing this file can significantly impact your site’s interaction with search engines. If you wish to have more control over the crawling and indexing of your website, creating a physical robots.txt file might be the right choice.
Remember, with great power comes great responsibility. Use the robots.txt file wisely to guide search engines effectively. If you have any further questions or need more help with your WordPress site, feel free to leave a comment below.
If you’re looking for fast wordpress hosting as well as done-for-you updates such as using robots.txt file wisely in your WordPress site. check out our hosting packages by clicking the button below:

Author: Erick Martinez
Erick Martinez is a WordPress veteran with a passion for the open web.




























